|
:: MVP ::
|

|
|
:: RSS ::
|

|
|
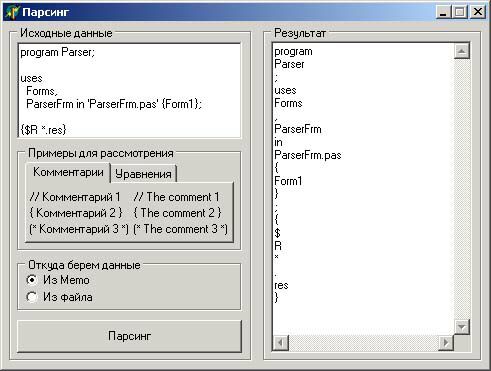
Рано или поздно каждый программист сталкивается с такой задачей. Если вы
еще не знаете, что это такое, коротко расскажу. Суть парсинга заключается
в разборе и анализе текста. Эту задачу можно решать разными способами:
разрабатывать свои собственные алгоритмы или использовать чужие, взятые
на сайтах с исходниками. Однако есть и другое, более простое решение.
Недокументированный класс TParser, который находится в модуле Classes,
предназначен для решения именно этой задачи. Концепция этого класс следующая:
он работает с потоком, и предоставляет доступ к своим составляющим, различая
их по типам.
Текст для разбора может находиться как в файле, так и в каком-либо текстовом
компоненте, например TMemo. Процедуры будут не сильно отличаться друг от друга,
тем не менее, приведу в пример обе.
// Разбор текста из файла
procedure FileParser;
var
Stream: TFileStream;
begin
Form1.MemoResult.Clear;
if Form1.OpenDialog.Execute then
begin
// Создаем поток и загружаем в него файл
Stream := TFileStream.Create( Form1.OpenDialog.FileName, fmOpenRead );
with TParser.Create( Stream ) do
// Пока не дошли до конца потока...
while Token <> toEof do
begin
Form1.MemoResult.Lines.Add( TokenString );
NextToken;
end;
Stream.Free;
end;
end;
// Разбор текста из Memo
procedure MemoParser;
var
Stream: TMemoryStream;
begin
Form1.MemoResult.Clear;
// Создаем поток
Stream := TMemoryStream.Create;
// Загружаем в него текст из Memo
Stream.WriteBuffer( AnsiString( Form1.MemoCode.Text )[1], Length( Form1.MemoCode.Text ) );
Stream.Position := 0;
with TParser.Create( Stream ) do
// Пока не дошли до конца потока...
while Token <> toEof do
begin
Form1.MemoResult.Lines.Add( TokenString );
NextToken;
end;
Stream.Free;
end;
|
Эти процедуры разберут текст от начала до конца, при этом механизм
его работы остается для нас полностью прозрачным. Но разбор текста,
это только половина дела, ведь TParser предоставляет нам механизмы
анализа текста непосредственно на этапе его разбора. Все составляющие
разобранного текста TParser автоматически причисляет к одному
из предопределенных в нем типов: toFloat - вещественное число, toInteger
- целое число, toSymbol - символ, toString - строка, toWString -
Unicode-строка, toEOF - конец потока. Итак, допустим, мы хотим извлечь
из текста только целые числа, тогда процедура MemoParser будет выглядеть
так:
procedure MemoParser;
var
Stream: TMemoryStream;
begin
Form1.MemoResult.Clear;
// Создаем поток
Stream := TMemoryStream.Create;
// Загружаем в него текст из Memo
Stream.WriteBuffer( AnsiString( Form1.MemoCode.Text )[1], Length( Form1.MemoCode.Text ) );
Stream.Position := 0;
with TParser.Create( Stream ) do
// Пока не дошли до конца потока...
while Token <> toEof do
begin
if Token = toInteger then
Form1.MemoResult.Lines.Add( TokenString );
NextToken;
end;
Stream.Free;
end;
|
Соответственно для вещественных чисел toInteger нужно заменить на
toFloat, для строк - на toString и т.д. по аналогии. Следует отметить,
строкой (toString) считается символ/группа символов, заключенных в
апострофы, в противном случае это toSymbol. Если же мы хотим
подсчитать, сколько раз в тексте встречается какой-либо знак (например,
знак '='), то процедуру мы перепишем так:
procedure MemoParser;
var
Stream: TMemoryStream;
Col: integer;
begin
Form1.MemoResult.Clear;
Col := 0;
// Создаем поток
Stream := TMemoryStream.Create;
// Загружаем в него текст из Memo
Stream.WriteBuffer( AnsiString( Form1.MemoCode.Text )[1], Length( Form1.MemoCode.Text ) );
Stream.Position := 0;
with TParser.Create( Stream ) do
// Пока не дошли до конца потока...
while Token <> toEof do
begin
if Token = '=' then
Inc( Col );
NextToken;
end;
Stream.Free;
Form1.MemoResult.Lines.Add( IntToStr( Col ) );
end;
|
Вот и все. Задача парсинга оказалось не такой уж и сложной, и описанное выше
вполне подойдет для решения большинства задач. Но есть моменты, которые в
некоторых ситуациях потребуют дополнительных усилий со стороны программиста,
или вовсе не позволят воспользоваться классом TParser, и придется решать задачу
по-другому. Коротко опишу эти моменты:
- Разбирая строку s с математическим выражением вида 3+2=5 или 3-2=1 мы получим
('3+2' '=' '5') и ('3-2' '=' '1') соответственно. Это неприемлемо, если
операторы и операнды нам нужны отдельно друг от друга (например, при
решении задачи "обратной польской записи" при помощи стеков). Тогда строку
s нужно дополнительно обработать: StringReplace(s, '+', ' + ', [rfReplaceAll,
rfIgnoreCase]) или StringReplace(s, '-', ' - ', [rfReplaceAll, rfIgnoreCase])
соответственно.
- Знаки апострофа интерпретируются по правилам Delphi: при разборе строки 'abc'
мы получим (abc), при разборе строки 'a''b''c' мы получим (a'b'c), а нечетное
количество апострофов вызовет ошибку в программе. Поэкспериментируйте с
апострофами сами, и вы все поймете.
- Русский текст не будет разобран по словам, если только слова не заключены в
апострофы, в противном случае TParser разберет русский текст по буквам.
Это только те моменты, которые мне удалось выявить в процессе написания данной
статьи, возможно, есть и другие. В завершении желаю вам удачных экспериментов с
классом TParser, я надеюсь, что когда-нибудь он вам поможет, а мне он уже помог и не раз.
.: Пример к данной статье :.
|
|
При использовании материала - ссылка на сайт обязательна
|
|

